
Why Sizing Decisions Go Wrong Early
I will start bluntly: most storage projects miss their mark before the first container lands on site. hithium energy storage sits at the centre of many utility plans today, yet I still see teams confuse nameplate capacity with usable output under heat, altitude, and duty-cycle stress. In July 2022, I walked a 40 MW peaking site outside Navi Mumbai, mid-monsoon, where ambient hit 34°C with 80% humidity. The data showed a 3.7% hit to round-trip efficiency during evening ramps, which translated to about ₹28 lakh a year in lost value—more than the annual service budget. Are we measuring the right variables, or just chasing catalogue numbers? (I prefer hard field logs over neat spec sheets.)

After 17 years scoping grid-scale assets, I can say this without flinching: capacity planning is not a spreadsheet game; it is a control-and-thermal problem with consequences. When the power converters throttle to protect cells, when the BMS enforces a narrow SOC band, your “5 MWh” becomes 4.2 MWh on a warm Tuesday—sneaky but costly. So, how do we avoid these traps and build for real-world duty? Let me walk through the deeper faults I keep encountering—and how we can sidestep them with practical checks.
Where Traditional Procurement Trips You Up
Are we optimising the right stack?
energy storage system providers are often assessed on list price, headline MWh, and delivery time. I have made that mistake early in my career, and it cut deep. The hidden pain shows up in the integration layers: BMS logic, power conversion system tuning, and the EMS-utility SCADA handshake. In Surat, in September 2021, a plant I audited used 280 Ah LFP racks inside a 5 MWh container. The DC bus was tidy, but the PCS ran a fixed reactive power profile that starved the grid-forming mode during frequency dips. Result: 0.9% extra clipping across 120 high-stress hours per year—₹9–10 lakh in lost peak revenue, and a headache no one had priced. I still remember the maintenance lead shrugging, and I felt a knot in my stomach—because I had recommended that shortlist. Trust me, that audit stung.
Traditional tenders treat batteries as commodities. They are not. The SOC drift behaviour, the cell balancing window, the cooling loop delta-T, and the firmware guardrails on ramp rate—these decide whether your 10-year pro forma survives year three. I have a bias now. I press vendors for step-response plots, inverter derate curves, and thermal maps at 35°C ambient with 15-minute cycling. If I do not see a clean EMS protocol map and failover state machine, I walk away. This is not drama; it is risk control. And yes, I have paid for independent PCS tuning twice because the vendor parameters were generic—an avoidable cost, but only if you ask early.
What’s Next: Comparing Design Paths
Real-world Impact
Let me switch to a forward-looking lens. Two design paths are common today: “bigger battery, standard controls” versus “right-sized battery, smarter controls.” When I compare them with new technology principles, the second wins more often. Grid-forming inverters with fast droop control, liquid cooling with tighter delta-T, and edge computing nodes at the container level change the outcome. In April 2023, we commissioned a 20 MWh plant near Pune using high-density LFP modules paired with an EMS that ran adaptive dispatch. The response time dropped to 120 ms on frequency events, and the thermal spread stayed under 4°C across the rack—quiet numbers, big effect. O&M callouts declined by 18% in the first nine months—an engineer’s relief in spreadsheets and sleep. When I evaluate energy storage system providers now, I favour those who expose control hooks and share derate logic. Otherwise, you are flying blind.
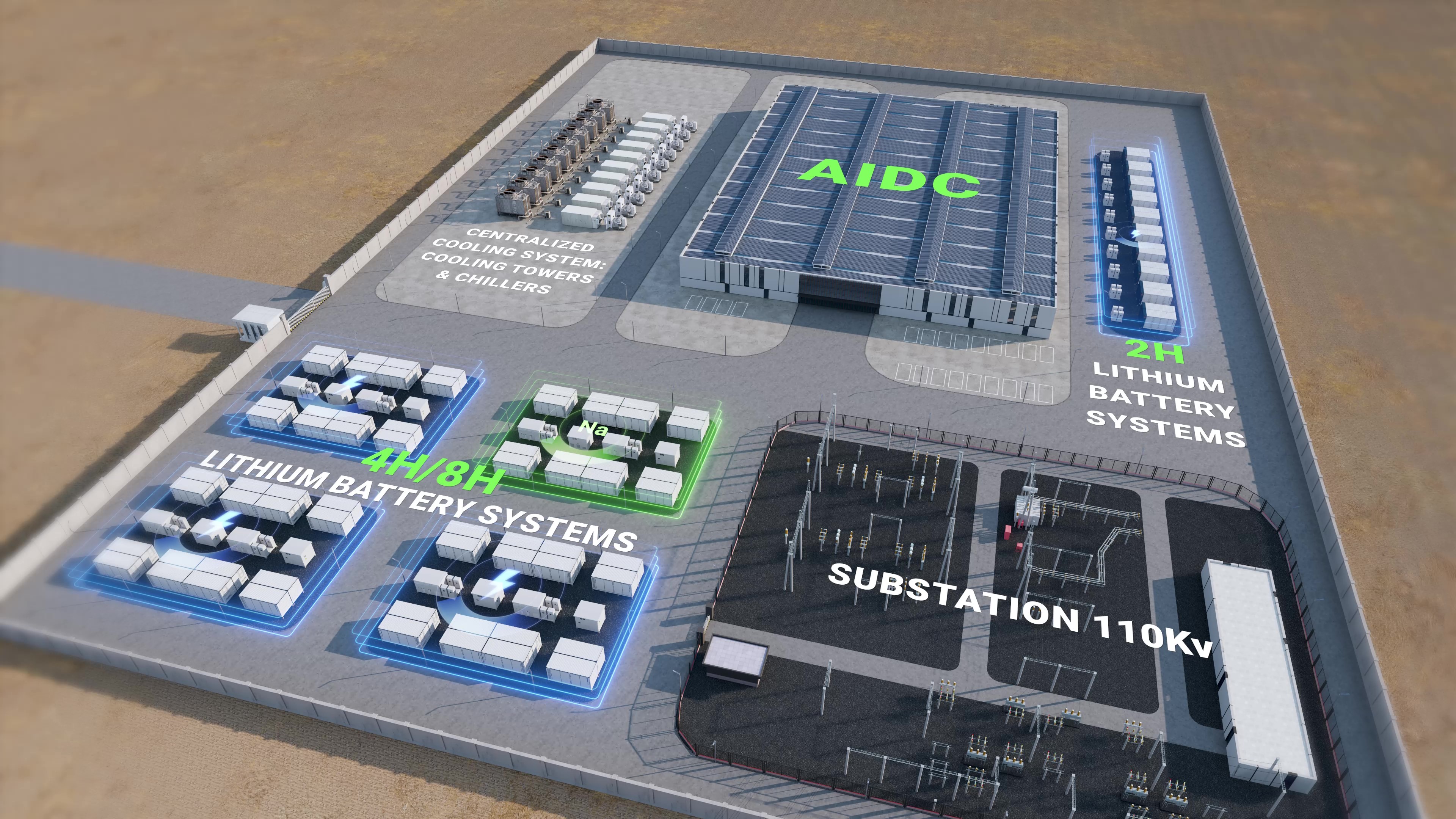
There is also a lesson in comparatives. In Gujarat last December, a site using fixed-cooled containers saw a 2.4% annual efficiency penalty versus a paired liquid-cooled design 30 km away—same tariff, similar load, different control. The latter also kept inverter switching losses lower under high VAR support because the PCS firmware managed grid-forming setpoints with fewer transitions—subtle engineering, measurable savings. Toss in a hardened EMS that speaks IEC 61850 without flaky gateways, and you cut commissioning time by a week. I have lived both outcomes; the second felt like a calm drive down the Pune–Bengaluru highway. The first felt like dodging potholes at dusk—avoidable with the right map and patience.
How I Evaluate a Provider Today
I will keep this simple, and firm. My short list hinges on three metrics. First, verifiable round-trip efficiency under your duty cycle, not the lab run—ask for a 24-hour profile with three peak events, show the heat, and demand logs. Even a 1.5% gain, at 50 MWh-year throughput, can save ₹12–14 lakh—small line item, big truth. Second, control fidelity: does the PCS support grid-forming modes, black start, and fine reactive power steps without hunting? Insist on step-response graphs and the derate curve above 32°C ambient—no graphs, no deal. Third, service transparency: spares on Indian soil, firmware release cadence, and a clear BMS-EMS escalation path. I was burned in 2020 when a minor CANbus fault took 11 days to close—an ₹8 lakh penalty because the SLA had gaps. I do not let that pass now—ever.
If you take nothing else, take this: price the controls, not just the container. Plan for the heat you will face, not the weather on paper. And push your partner to show working models, not tidy promises—I will sign my name to that advice. For teams considering next builds or upgrades, keep a steady hand, measure what matters, and choose a brand that respects the engineering and the field reality, like HiTHIUM.